
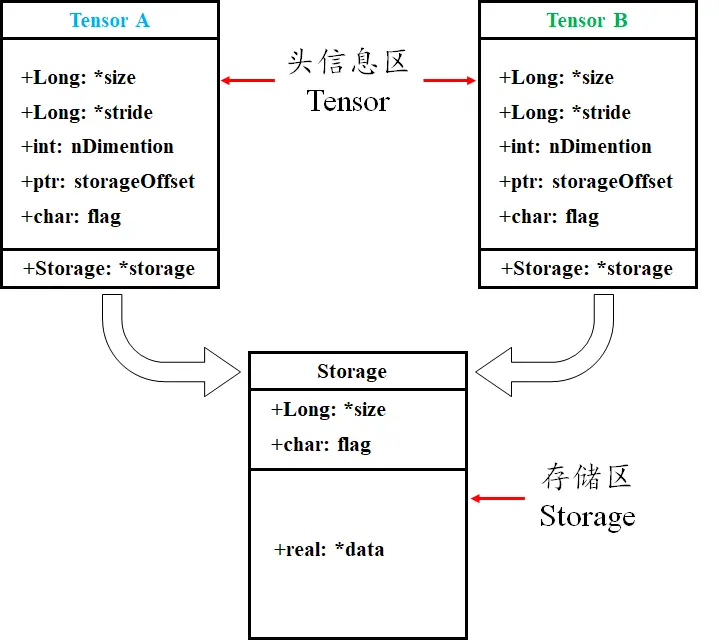
Pytorch基础知识(一)
一、pytorch环境部署
1. 安装conda
conda 是一个开源的软件包管理系统和环境管理软件,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。conda 是为Python程序创建的,类似于 Linux、MacOS、Windows,也可以打包和分发其他软件。
注意:必须在 cmd 里面才可以,在 powershell 里面输入命令有些是无效的
2. 创建Python环境
创建环境
1 | conda create -n name python=3.8 ##示例,实际根据需求选择Python版本以及设置环境名称 |
激活环境
1 | conda activate name |
退出环境
1 | conda deavtivate |
查看环境下包的信息
1 | pip list # 列出pip环境里的所有包 |
3. 安装NVIDIA CUDA以及CUDNN(若没有GPU可以跳过本步骤)
3.1 查看本机GPU信息
在CMD控制台中输入以下命令就可以查看本机GPU型号以及其适配CUDA型号信息
1 | nvidia-smi # 查看本机GPU型号以及其适配CUDA的信息 |
3.2 安装CUDA
下载CUDA安装包,下载地址:https://developer.nvidia.com/cuda-downloads
- 选择Windows或者Linux,选择对应版本的CUDA安装包
安装CUDA安装包
- 默认安装即可,如果出现错误,可以参考:https://blog.csdn.net/weixin_53762670/article/details/131845364
验证CUDA安装是否成功
- 打开cmd,输入以下命令
1
nvcc -V
如果出现以下信息,则说明安装成功
1
2
3
4nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Wed_Jun__2_19:15:15_Pacific_Daylight_Time_2021
Cuda compilation tools, release 11.5, V11.5.119安装CUDNN
- 下载CUDNN安装包,下载地址:https://developer.nvidia.com/cudnn
- 选择对应CUDA版本的CUDNN安装包
- 将下载后的压缩包解压到CUDA安装的根目录下,例如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5
验证CUDNN安装是否成功
- 进入到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite 目录下,在上方文件路径中输入CMD,
然后回车,进入到该目录命令窗口下,首先输入bandwidth.exe,如果出现以下信息,则说明安装成功 
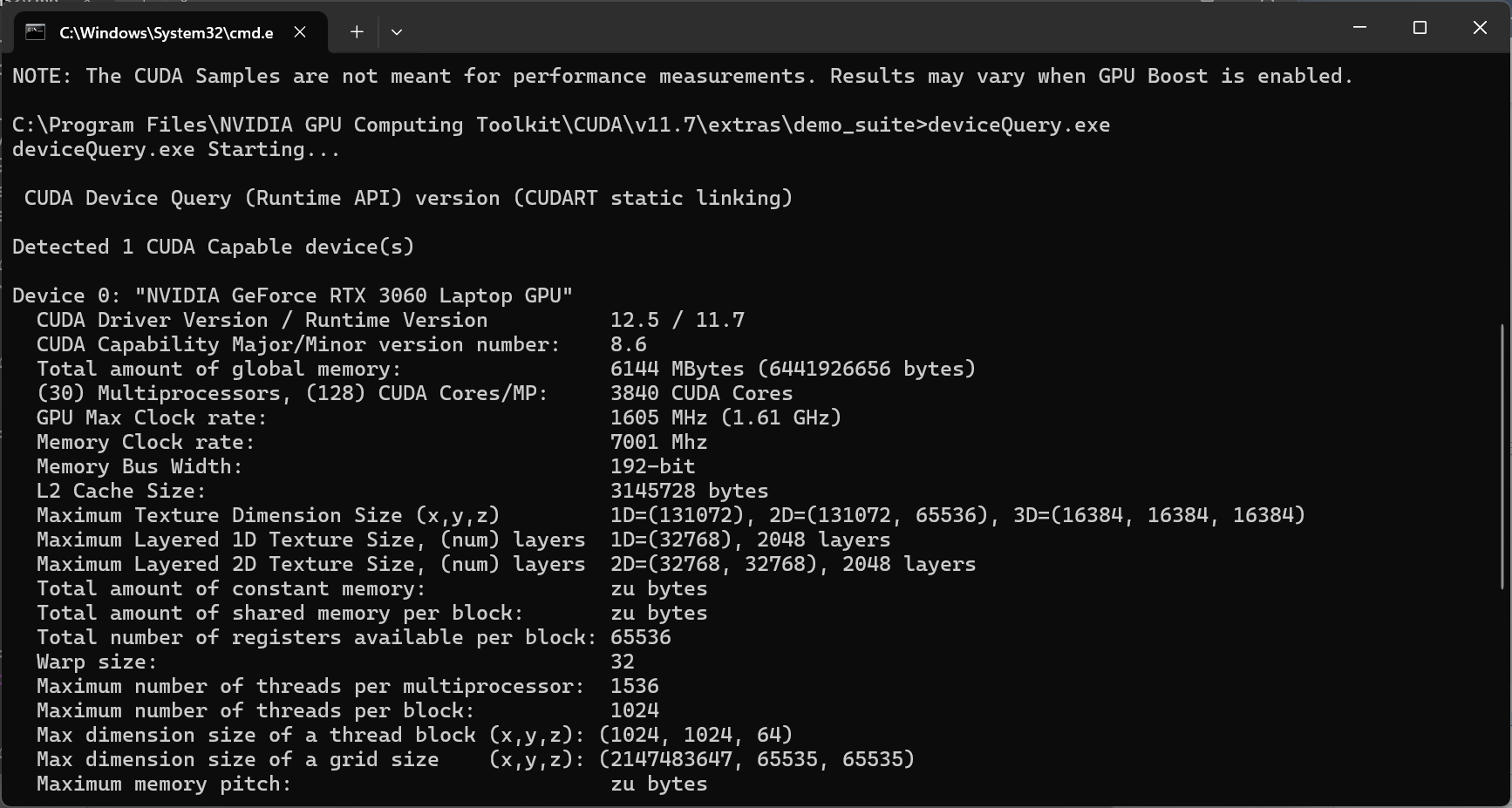
- 然后在输入deviceQuery.exe,如果出现以下信息,则说明安装成功
- 进入到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite 目录下,在上方文件路径中输入CMD,
4. 安装Pytorch
1. 安装Pytorch相关包
输入以下命令安装Pytorch
1 | conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia ## 注意pytorch-cuda版本替换为自己实际的CUDA版本 |
2. 验证Pytorch安装是否成功
- 打开cmd,输入以下命令
1 | conda activate name # 激活对应环境 |
- 如果出现以下信息,则说明安装成功,可以使用GPU进行训练
1 | >> import torch |
二、处理数据
1. 数据集的加载
1 | import torchvision |
Dataset介绍:
- Dataset 是一个抽象类,不能直接使用,需要继承 Dataset 类,然后重写 getitem 和 len 方法,这两个方法都是抽象方法,必须实现。
- getitem 方法用于获取数据集的某一个样本,返回一个样本。
- len 方法用于获取数据集的长度,返回一个整数。
1 | from torch.utils.data import Dataset |
DataLoader介绍:
- DataLoader 是一个迭代器,用于加载数据集。 可以通过 DataLoader 的参数设置,如 batch_size、shuffle、num_workers 等,来控制加载数据的方式。
1 | import torchvision |
三、 搭建网络
nn.Module介绍:
- nn.Module 是一个抽象类,不能直接使用,需要继承 nn.Module 类,然后重写 forward 方法,这个方法就是网络结构。
- forward 方法用于定义网络结构,返回一个张量。
1 | from torch import nn |
搭建网络:
1 | import torch |
损失函数:
1 | import torch |
优化器:
1 | import torch |
GPU的使用:
1 | fff = model.cuda() |
1 | device = torch.device("cuda") |
现有模型使用:
1 | vgg16_true = torchvision.models.vgg16(pretrained=True) |
保存读取网络:
1 | import torch |
四、完整的训练验证流程
1 | model.py |
1 | main.py |
1 | test.py |

评论